
Teil 1 in diesem Heft führt in die Problematik ein und behandelt die Objekterkennung mittels neuronaler Netzwerke.
As part of a graduation thesis, a system was developed with which convolutional neural networks (CNN) can be trained to reliably identify electronic components in X-ray images. The concept of transfer learning is used to train the CNNs. A procedure was designed and implemented to generate suitable training data sets. With the help of the training data sets, different network architectures for image classification and object detection could be trained and evaluated. For the transfer learning, freely available models from another domain were used. The results show that transfer learning is a suitable method to reduce the effort (time, amount of data) in creating classification and object detector models. The models created show a high degree of accuracy in classification and object detection, even with unknown data. Applications that are related to the evaluation of radiographic images of electronic assemblies can be designed more effectively thanks to the available knowledge.
Part 1 in this issue introduces the problem and deals with object recognition using neural networks.

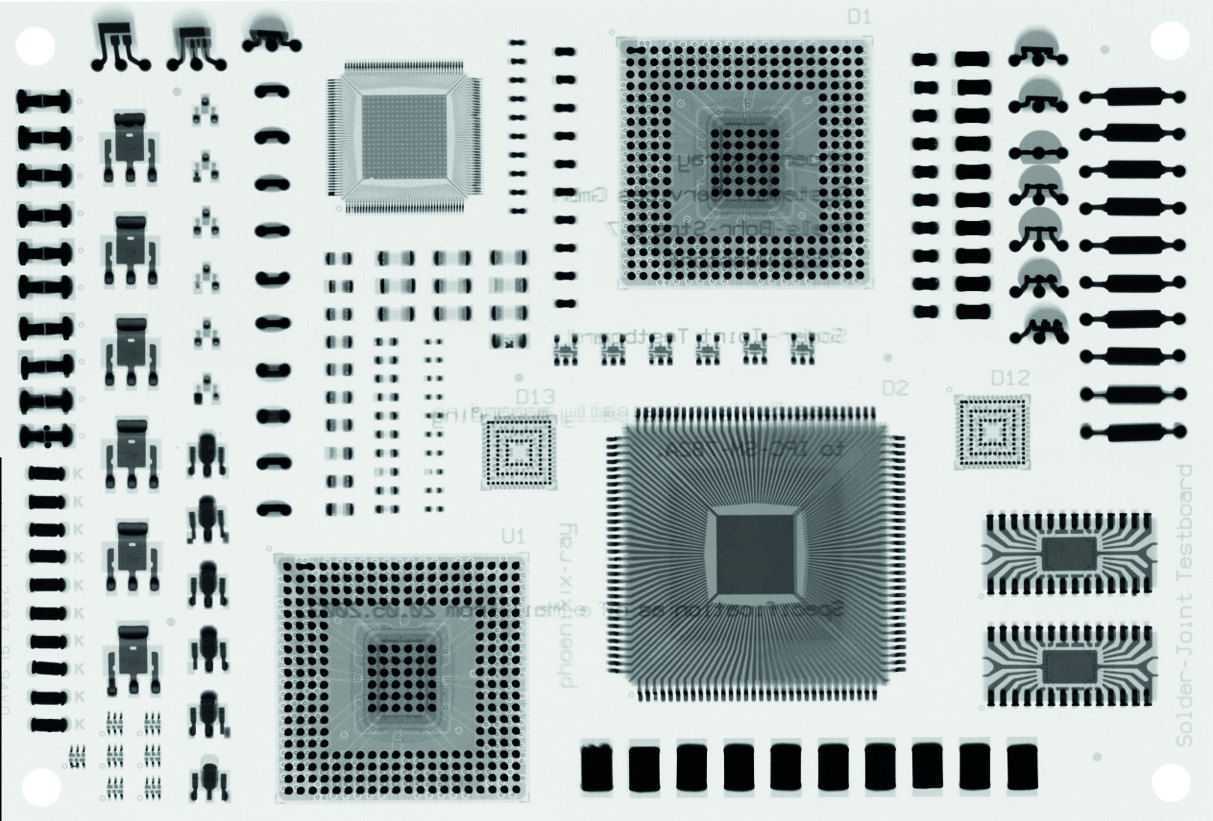
Abb. 1: Links die Testbaugruppe (phoenix x-ray), rechts das zugehörige Röntgenbild
Motivation
Die zerstörungsfreie Prüfung und Beurteilung elektronischer Baugruppen und Bauelemente ist ein Teilbereich der Aufbau- und Verbindungstechnik (AVT). Häufig wird bei der Untersuchung der Lötstellen von Ball-Grid-Arrays (BGA) oder gehäusten Modulen mit unbekannten Bauelementen die Röntgenbildgebung verwendet, um verdeckte Strukturen sichtbar zu machen. Da sich Röntgenbilder der untersuchten Bauelemente bzw. Baugruppen jedoch deutlich von deren äußeren Erscheinungsbildern unterscheiden, kann es für den Betrachter mitunter schwierig sein, Strukturen zu identifizieren und ergänzend festzustellen, ob diese Störungen oder andere Auffälligkeiten aufweisen. Abbildung 1 zeigt die Unterschiede an einem praktischen Beispiel in Form einer Testbaugruppe. Im äußeren Erscheinungsbild anhand eines Fotos oder durch bloßes Betrachten lassen sich die verschiedenen Komponenten anhand ihrer Kontur, Beschriftung und Farbgebung voneinander differenzieren. Diese Objektmerkmale sind hingegen mit der Radiografie meist nicht zu identifizieren. Sie offenbart aber neue Informationen über das Innere von Komponenten und zu verdeckten Lötstellen.
Ein BGA erscheint im Röntgenbild auf den ersten Blick häufig nur noch als definierte Ansammlung vieler runder Lötkontakte. Beim genaueren Betrachten können auch Bonddrähte bzw. Flip-Chip-Kontakte oder der Interposer mit Durchkontaktierungen als charakteristische Eigenschaften erkannt werden. Die Erkennbarkeit spezifischer Eigenschaften lässt sich auf viele weitere Package-Typen ausweiten, setzt jedoch eine Grundkenntnis zum inneren Aufbau voraus.
 Abb. 2: CNN – Einordnung in die Welt der KI
Abb. 2: CNN – Einordnung in die Welt der KI
Daher rührt die Überlegung, Aufnahmen automatisch mit zusätzlichen Informationen anzureichern, die dem Betrachter die Erkennung und Beurteilung erleichtern. Somit kann die Bewertung von Röntgenaufnahmen elektronischer Baugruppen im Rahmen der Qualitätssicherung, aber insbesondere bei der Fehlersuche verbessert werden. Das ist bis dato ein zumeist aufwendiger manueller Prozess, bei dem die individuelle Erfahrung des Bewertenden eine entscheidende Rolle spielt. Im Rahmen einer Graduierungsarbeit wurde an der TU Dresden ein System entwickelt, mit dem Convolutional Neural Networks (CNN) trainiert werden können, um in Röntgenaufnahmen elektronische Bauelemente sicher zu erkennen. Die wesentlichen Erkenntnisse und Ergebnisse dieser Arbeit werden in diesem Artikel vorgestellt. Sie zeigen, dass das Konzept des Transfer Learning eine geeignete Methode zur Reduzierung des Aufwands (Zeit, Datenmenge) bei der Erstellung von Klassifizierungs- und Objektdetektor-Modellen ist. Die erstellten Modelle zeigen dabei eine hohe Genauigkeit bei der Klassifikation und Objektdetektion auch bei unbekannten Ausgangsdaten.
1 Einleitung
Die automatische Objekterkennung in Bildern ist ein aktuelles Thema und erfährt durch die Verwendung von Methoden des maschinellen Lernens (ML) eine rasante Entwicklung [1]. In diesem Kontext kommen insbesondere Verfahren zum Einsatz, die auf der Nutzung von CNN basieren. CNNs lassen sich als ein Teilbereich des Konzepts Künstliche Intelligenz (KI) verstehen. Für ein besseres Verständnis der Begrifflichkeiten rund um die KI ist es wichtig, einige näher zu beschreiben bzw. zu unterscheiden. Die KI setzt sich im Allgemeinen mit der Automatisierung von intelligentem Verhalten auseinander. Das Ziel ist die Nachbildung menschlicher Entscheidungsstrukturen bzw. die eigenständige Bearbeitung von Problemstellungen. ML ist ein Teilbereich der KI und umfasst die Aufgabenbereiche der künstlichen Generierung von Wissen aus Erfahrung. Dafür werden in vorliegenden Datenbeständen wiederkehrende Muster erkannt, verallgemeinert und für die Analyse unbekannter Daten angewendet. Deep Learning (DL) ist wiederum ein Teilbereich des ML bzw. eine spezielle Methode der Datenverarbeitung mittels mehrschichtiger (deep) Neuronaler Netze. DL-Systeme können die Informationsverarbeitung des Menschen nachahmen und können ohne äußere Anleitung lernen. DL eignet sich insbesondere für die Mustererkennung aus sehr großen Datenbeständen. CNN gehören zu dem Gebiet des DL. Ein weiterer wichtiger Teilbereich sind das maschinelle Sehen bzw. Computer Vision, die in digitalen Bildmaterialien Objekte identifizieren sowie relevante Informationen extrahieren und verarbeiten können [2]. Abbildung 2 stellt diese Form der Einordung kompakt dar.
Das Training neuronaler Netze benötigt grundsätzlich eine große Menge annotierter Datensätze, um zugrundeliegende Strukturen und Muster erkennen zu können. Dies stellt im vorliegenden Kontext der Prüfung und Beurteilung elektronischer Baugruppen und Bauelemente jedoch eine besondere Schwierigkeit dar, da bisher keine geeigneten Datensätze zur Verfügung stehen. Das Erzeugen eines Datensatzes gilt wiederum als aufwendigster und teuerster Prozess bei dem Entwurf derartiger Systeme. Um diesem Problem zu begegnen, wird das Konzept des Transfer Learning (TL) vorgestellt. Mit diesem soll zumindest theoretisch die benötigte Datenmenge deutlich reduziert werden können. Ähnlich wie beim Menschen lässt sich das ‚Wissen' über Strukturen von einer Domäne in eine andere übertragen. Das ist beispielsweise mit dem Lernen einer neuen Sprache vergleichbar. Im Kontext von Bildverarbeitung mit CNNs wird sich dabei die Ähnlichkeit des Bildaufbaus zunutze gemacht. Ein Bild kann als Ansammlung vieler Ecken, Kanten, Kreise, Farben usw. gesehen werden. Diese groben Strukturen bilden Formen, die Kombination aus Formen bildet Objekte. Es ist bekannt, dass CNNs Bilder auf diese Art und Weise verarbeiten und so zunächst sehr grobe Merkmale extrahieren, die im weiteren Verlauf zu spezifischen Merkmalen heranwachsen. Für die Bildverarbeitung von alltäglichen Objekten stehen heute eine Vielzahl unterschiedlicher Modelle zur Verfügung, die direkt verwendet werden können. Zwischen Röntgenaufnahmen und Lichtbildern existieren jedoch deutliche Unterschiede (Graustufen, Art der Abbildung, ...). Deshalb musste untersucht werden, ob und wie gut sich diese Modelle in den Kontext der Radiografie transferieren lassen. Dabei wird im Allgemeinem zwischen der Bildklassifikation und Objektdetektion unterschieden. Auf Basis einer (halb-)automatischen Erzeugung von Baugruppen und der Annotation auf Basis von Entwurfsdaten wurden geeignete Datensätze mit verhältnismäßig geringem Aufwand entwickelt und umgesetzt.
2 Objekterkennung allgemein
Unter dem Begriff der Objekterkennung können generell in der computergestützten Bildverarbeitung unterschiedliche Aufgaben verstanden und nach ihrer Komplexität wie in Tabelle 1 gegliedert werden.
Die erste Aufgabe ist die ‚Klassifikation'. Dabei wird dem Eingangsbild ein Label mit der wahrscheinlichsten Klasse zugeordnet. Sollten mehrere Objekte im Bild enthalten sein, wird dennoch nur ein Label ausgegeben. Aus diesem Grund sollte nach Möglichkeit nur ein Objekt im Bild enthalten sein Das nachfolgende Beispiel der Klassifikationsaufgabe zeigt die Ausgabe für ein Objekt. bei dem es sich mit 97 % Wahrscheinlichkeit (P) um einen Chip-Widerstand (CR) handelt.
|
Aufgabe |
Eingabe |
Ausgabe |
Limitierung |
|
Klassifikation: Zuordnung eines Klassenlabels |
 |
 |
max. 1 Objekt bzw. Bild |
|
Klassifikation + Lokalisation: Zuordnung eines Klassenlabels und Objektkoordinaten |
 |
|
max. 1 Objekt bzw. Bild |
|
Objektdetektion: Identifikation von verschiedenen Objekten und deren Position |
 |
|
keine |


Bei der zweiten Aufgabe handelt es sich um eine ‚Klassifikation und Lokalisation'. Hier wird neben dem Label der wahrscheinlichsten Klasse zusätzlich die Position des umgebenden Rechtecks ausgegeben. Auch in diesem Fall kann nur ein Objekt verarbeitet werden.
Die dritte und komplexeste Aufgabe ist die ‚Objektdetektion'. Hierbei soll festgestellt werden, welches Objekt sich an welchem Ort im Bild befindet. Das Eingangsbild kann dabei eine beliebige Anzahl von Objekten aus unterschiedlichen Klassen enthalten.
Die Wirkungsweise eines Objektdetektors umfasst in der Regel zwei Arbeitsmodi. Der erste Modus wird häufig als Training bezeichnet und dient der Erstellung eines Modells der gesuchten Objekte bzw. Objektklassen. Der zweite Modus wird Inference (Deutsch: Inferenz – logische Schlussfolgerung) genannt. In diesem Modus versucht der Detektor mithilfe des Modells die Eingangsdaten auszuwerten.
Die Objekterkennung in Bilddaten erfolgt in den meisten Fällen in zwei bis drei Schritten. Im ersten Schritt werden die Eingangsdaten vorverarbeitet. Das kann beispielsweise eine Größenänderung, die Konvertierung in ein anderes Datenformat oder die Änderung des Farbraumes sein. Im zweiten Schritt findet die Objektdetektion statt. Dabei wird das Bild segmentiert bzw. Regionen von Interesse (RoI, Region of Interest) werden ermittelt. Im dritten Schritt führt der Algorithmus eine Klassifizierung der Regionen bzw. der Objekte (Bildausschnitte) durch. Dabei werden diese mit einem Modell verglichen und so ein Grad der Übereinstimmung ermittelt. Für die Qualität der Klassifizierung bildet das Datenmodell die Grundlage.
Die Vorbereitung dieses Datenmodells (Training) funktioniert ähnlich zum Pfad der Inferenz. Für ein gutes Modell ist grundsätzlich eine große Anzahl annotierter Daten mit einer hohen Variation notwendig. Je größer der basierende Datensatz, desto robuster und präziser ist das Resultat der Klassifikation. Es gibt unterschiedliche Verfahren, mit denen ein Objektdetektor realisiert werden kann. Dazu gehören ‚konventionelle' Methoden, zu denen Verfahren auf Basis von Template Matching oder Merkmalserkennung gehören. Diese werden jedoch nur der Vollständigkeit halber erwähnt und im weiteren Verlauf nicht weiter betrachtet.
Mit der Veröffentlichung von AlexNet im Jahr 2012 sind Verfahren auf Basis neuronaler Netze in den Fokus gerückt [3]. Diese ‚neuartigen' Verfahren liefern deutlich präzisiere Ergebnisse. Die Neuartigkeit dieser Methoden ist in dem adaptiven Lernprozess begründet. Der Entwickler muss selbst keine Merkmale der zu untersuchenden Objekte festlegen, da das Modell selbstständig die zugrundeliegenden Strukturen erkennt.
3 Objekterkennung mit CNN
Wie bereits anfangs erwähnt, kommen für die automatische Objekterkennung in Bildern immer häufiger CNN zum Einsatz. Diese verfügen über eine Eingabeschicht, eine Ausgabeschicht und eine beliebige Anzahl von ‚versteckten' Schichten, den sogenannten Hidden Layers. Die Hidden Layers erfüllen dabei mehrere Funktionen und bestehen aus unterschiedlichen Modulen. Zu diesen Modulen gehören unter anderem die sogenannten Convolutional Layers. In diesen werden Filter-Kernel (Operatoren) mit einer Faltungsoperation (Convolution) auf die Bilddaten angewendet, um Merkmale (Features) zu extrahieren. Die Faltungsoperation entspricht dabei einer Matrixmultiplikation mit einer Feature Map als Ergebnis. Des Weiteren werden Pooling Layer eingesetzt, um diese Informationen zu verdichten. Häufig wird das sogenannte Max Pooling eingesetzt. Dabei handelt es sich um einen Maximum-Operator einer bestimmten Größe (Kernel Size) und Schrittweite (Stride). Je komplexer die Erkennungsaufgabe, desto größer ist die Zahl der Schichten zwischen Ein- und Ausgabe. Man spricht dabei von der Tiefe (Depth, sequentielle Strukturen) und Breite (Width, parallele Strukturen) eines Netzes. Das Design solcher Netze ist neben dem Entwurf von Detektorarchitekturen Gegenstand aktueller Forschung und Entwicklung.
![Abb. 3: Beispielhafte Darstellung der Ergebnisse (Feature Maps) der fünf Convolution-Blöcke eines VGG-16 (VGG16 ist eine von 6 vortrainierten Architekturen von VGG Net – Visual Geometry Group – mit 16 gewichteten Layern). Unter den Grafiken sind die jeweiligen Auflösungen und Anzahlen der Einzelbilder dargestellt [4]](/images/stories/Abo-2022-10/plus-2022-10-1011.jpg "Abb. 3: Beispielhafte Darstellung der Ergebnisse (Feature Maps) der fünf Convolution-Blöcke eines VGG-16 (VGG16 ist eine von 6 vortrainierten Architekturen von VGG Net – Visual Geometry Group – mit 16 gewichteten Layern). Unter den Grafiken sind die jeweiligen Auflösungen und Anzahlen der Einzelbilder dargestellt [4]") Abb. 3: Beispielhafte Darstellung der Ergebnisse (Feature Maps) der fünf Convolution-Blöcke eines VGG-16 (VGG16 ist eine von 6 vortrainierten Architekturen von VGG Net – Visual Geometry Group – mit 16 gewichteten Layern). Unter den Grafiken sind die jeweiligen Auflösungen und Anzahlen der Einzelbilder dargestellt [4]
Abb. 3: Beispielhafte Darstellung der Ergebnisse (Feature Maps) der fünf Convolution-Blöcke eines VGG-16 (VGG16 ist eine von 6 vortrainierten Architekturen von VGG Net – Visual Geometry Group – mit 16 gewichteten Layern). Unter den Grafiken sind die jeweiligen Auflösungen und Anzahlen der Einzelbilder dargestellt [4]
In den extrahierten Merkmalen aus den vorherigen Schichten (Feature Maps) werden durch voll vernetzte Schichten (Fully Connected Layers, kurz: FC) Muster erkannt. Dabei besteht jede der voll vernetzten Schichten aus Knotenpunkten (Neuronen), die mit den Knoten der nächsten Schicht verbunden sind. Jedes Neuron besitzt eine Aktivierungsfunktion, die bestimmt, ob es seine Information weiterleitet oder nicht. Dazu wird aus den verbundenen und aktivierten Neuronen (der vorherigen Schicht) eine gewichtete Summe gebildet. Jede Verbindung besitzt dabei ein eigenes Gewicht (Weight). Zu dieser gewichteten Summe wird eine Konstante (Bias) addiert. Diese Summe bildet das Argument der Aktivierungsfunktion. Häufig kommt dabei eine ReLU (Rectified Linear Unit – Rechteckfunktion) zum Einsatz. Diese Gewichte und Konstanten werden bei der Erstellung des Netzwerks mit zufälligen Werten initialisiert. In einem Trainingsprozess werden sowohl die Gewichte und Konstanten, als auch Werte der Filter-Kernel (Shared Weights) in den Convolution Layers angepasst. Je nach Netzwerkmodell bewegt sich die Zahl der anpassbaren Parameter im Bereich von wenigen Millionen (Fokus: Geschwindigkeit, mobile Anwendungen) bis über eine Milliarde (Fokus: Genauigkeit). Zwischen der Zahl der trainierbaren Parameter und den benötigten Trainingsdaten besteht ein nahezu linearer Zusammenhang [5].
Für die Bildklassifikation und Merkmalsextraktion stehen bereits heute eine Vielzahl unterschiedlicher CNNs zur Verfügung. Diese werden i. d. R. mithilfe von großen, öffentlichen Datensätzen (ImageNet, Microsoft COCO, CIFAR 10/100, ...) trainiert, evaluiert und verglichen. Diese Datensätze umfassen meist Aufnahmen von Objekten des täglichen Lebens, die auf digitalen Farbfotografien basieren. Die datenresultierenden CNN kennen keine Röntgenbilder von Bauelementen und Baugruppen, wie sie für den Zweck dieser Untersuchung benötigt werden. Sie bieten jedoch eine Vielzahl von Bildfilteroperatoren, die mit notwendigen Anpassungen ebenfalls auf Röntgenbilder angewendet werden können.
Neben der Bildklassifikation spielt die Objektdetektion eine große Rolle. Innerhalb der Objektdetektoren werden aus den Bilddaten mithilfe eines CNN (Backbone) Merkmale (Feature Maps) extrahiert. Im Gegensatz zur Klassifikation durchlaufen diese Merkmale nun zusätzliche Netzwerke, mit denen RoI detektiert werden können. Da es hierbei zu einer sehr hohen Anzahl potenzieller Regionen kommen kann, werden diese durch sogenanntes Pooling reduziert. Bei den Regionsvorschlägen gibt es häufig Überlappungen, sodass für ein Objekt mehrere Objektgrenzen vorgeschlagen werden. Diese können mithilfe spezieller Methoden reduziert werden. Neben der Vorhersage der korrekten Objektklasse (Klassifikation) ist die korrekte Vorhersage der Objektgrenzen (Regression) eine wesentliche Aufgabe, die durch einen Objektdetektor gewährleistet wird.
4 Transfer Learning
Den Ablauf der Bildklassifikation mittels CNN kann man sich in kompakter Form wie in Abbildung 4 vorstellen. Das Modell besteht aus dem sogenannten Backbone und dem Head. Der Backbone generiert durch Anwendung von Filtern Merkmale (Features) aus den Eingangsdaten und erzeugt Feature Maps. Diese werden im Head klassifiziert. Bei einem neu initialisierten neuronalen Netz sind die Filter zunächst sehr unspezifisch und werden im Rahmen des Trainings verfeinert und optimiert. Die Neuinitialisierung eines CNN ist jedoch sehr zeit- und rechenintensiv und benötigt eine sehr große Anzahl annotierter Datensätze, d. h. mehrere 100 Bilder pro Objektklasse. Annotation bedeutet in diesem Zusammenhang die Verknüpfung eines Bildes mit dem entsprechenden Klassenlabel.
 Abb. 4: Ablauf einer Bildklassifikation
Abb. 4: Ablauf einer Bildklassifikation
Die Erzeugung eines Datensatzes gilt im Allgemeinen als aufwendigster und teuerster Prozess. Der Aufwand kann jedoch reduziert werden durch die Übertragung des Wissens eines vortrainierten neuronalen Netzes zur Lösung einer Aufgabe auf eine neue Aufgabe bzw. Anwendung. Das sogenannte Transfer Learning läuft prinzipiell gleich zur Klassifikation ab, wobei hier ein bereits trainiertes Modell modifiziert und weiter optimiert wird.
Für das Transfer Learning stehen grundsätzlich unterschiedliche Szenarien der Modifikation zur Verfügung und folgen dabei dem Schema:
- Auswahl eines Basisnetzwerks
- Kopieren der ersten n Schichten (Filter-Kernel)
- Trainieren des Netzwerks mit dem Zieldatensatz
Die Konfiguration des Zielnetzwerks (Wahl des Basisnetzwerks, die Zahl der transferierten bzw. neu initialisierten Schichten) ist frei in der Gestaltung und bleibt dem Anwender überlassen. Die genannten Parameter hängen jedoch von der Größe des Datensatzes, der Ähnlichkeit mit der Quelldomäne und der Anwendung ab und müssen in der Regel experimentell ermittelt werden. Generell wird empfohlen, vor allem bei sehr kleinen Datensätzen, lediglich die letzte Schicht auszutauschen und durch einen linearen Klassifikator zu ersetzen [6].
 Ausgangspunkt: Vortrainiertes Netz für eine bestimmte Aufgabe") (a) Ausgangspunkt: Vortrainiertes Netz für eine bestimmte Aufgabe
(a) Ausgangspunkt: Vortrainiertes Netz für eine bestimmte Aufgabe
 Szenario 1: Die vortrainierte Netzarchitektur wird vollständig transferiert. Die einzelnen Schichten können während des Trainings optimiert werden") (b) Szenario 1: Die vortrainierte Netzarchitektur wird vollständig transferiert. Die einzelnen Schichten können während des Trainings optimiert werden
(b) Szenario 1: Die vortrainierte Netzarchitektur wird vollständig transferiert. Die einzelnen Schichten können während des Trainings optimiert werden
 Szenario 2: Es werden die ersten n Schichten transferiert und die letzten zwei mit zufälligen Werten initialisiert. Die transferierten Schichten können, die neu initialisierten müssen trainiert werden") (c) Szenario 2: Es werden die ersten n Schichten transferiert und die letzten zwei mit zufälligen Werten initialisiert. Die transferierten Schichten können, die neu initialisierten müssen trainiert werden
(c) Szenario 2: Es werden die ersten n Schichten transferiert und die letzten zwei mit zufälligen Werten initialisiert. Die transferierten Schichten können, die neu initialisierten müssen trainiert werden
![(d) Szenario 3: Das Netzwerk wird transferiert, nach der dritten Schicht abgeschnitten und zwei neue Schichten angehängt, nach [6]](/images/stories/Abo-2022-10/plus-2022-10-1016.jpg "(d) Szenario 3: Das Netzwerk wird transferiert, nach der dritten Schicht abgeschnitten und zwei neue Schichten angehängt, nach [6]") (d) Szenario 3: Das Netzwerk wird transferiert, nach der dritten Schicht abgeschnitten und zwei neue Schichten angehängt, nach [6]
(d) Szenario 3: Das Netzwerk wird transferiert, nach der dritten Schicht abgeschnitten und zwei neue Schichten angehängt, nach [6]
Literatur
[1] K. Schmidt et al.: Enhanced X-Ray Inspection of Solder Joints in SMT Electronics Production using Convolutional Neural Networks, 2020 IEEE 26th Int. Symp. Des. Technol. Electron. Packag. SIITME 2020 - Conf. Proc., 2020, 26–31, doi: 10.1109/SIITME50350.2020.9292292
[2] Künstliche Intelligenz – was ist KI überhaupt?, 2022. https://www.optadata.at/journal/ki-begriffsdefinitionen/
[3] Z. Zou; Z. Shi; Y. Guo; J. Ye: Object Detection in 20 Years: A Survey, 2019, 1–39, 2019, [Online], Available: http://arxiv.org/abs/1905.05055
[4] PlotNeuralNet, https://github.com/HarisIqbal88/PlotNeuralNet
[5] M. Haldar: How much training data do you need?, https://malay-haldar.medium.com/how-much-training-data-do-you-need-da8ec091e956
[6] J. Yosinski; J. Clune; Y. Bengio; H. Lipson: How transferable are features in deep neural networks?, Adv. Neural Inf. Process. Syst., vol. 4, no. January, 2014, 3320–3328











