The large AI language model of the OpenGPT-X research project is now available for download on Hugging Face: The model, named 'Teuken-7B', has been trained with all 24 official languages of the EU. Researchers and companies can use the commercially available open source model for their own artificial intelligence (AI) applications.
The large AI language model of the OpenGPT-X research project is now available for download on Hugging Face: The model, called 'Teuken-7B', has been trained with all 24 official languages of the EU. Researchers and companies can use the commercially usable open source model for their own artificial intelligence (AI) applications.
The funded consortium project led by the Fraunhofer Institutes for Intelligent Analysis and Information Systems IAIS and for Integrated Circuits IIS has launched a large AI language model as a freely usable open source model with a European perspective. In the OpenGPT-X project, the partners from science and industry have spent the past two years researching the basic technology for large AI fundamental models and training corresponding models. The resulting model 'Teuken-7B' is now freely available worldwide, making it a public research alternative for science and business.
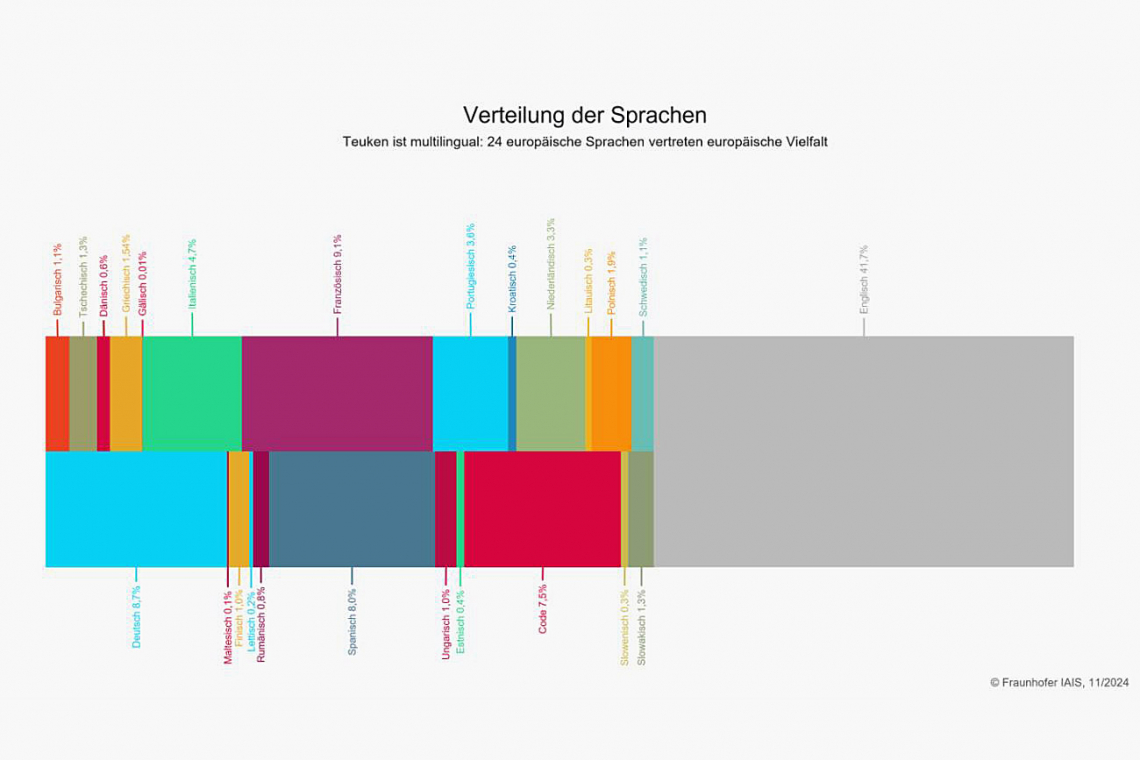
Teuken-7B is currently one of the few AI language models that have been developed multilingually from scratch. It contains around 50% non-English pre-training data and has been trained in all 24 official European languages. It has proven to be stable and reliable in its performance across multiple languages. This is a decisive advantage, especially for international companies that communicate in many languages. The provision as an open source model makes it possible to run your own customized models in real applications. Sensitive data can remain within the company.
The project team also addressed the question of how multilingual AI language models can be trained and operated in a more energy- and cost-efficient manner. To this end, a multilingual 'tokenizer' was developed in the project. The task of a tokenizer is to break down words into individual word components - the fewer tokens, the more (energy-) efficiently and quickly a language model generates the answer. The developed tokenizer led to a reduction in training costs compared to other multilingual tokenizers, such as Llama3 or Mistral. This is particularly important for European languages with long words such as German, Finnish or Hungarian. It can also increase efficiency in the operation of multilingual AI applications.
Teuken-7B is also accessible via the Gaia-X infrastructure. Players in the Gaia-X ecosystem can thus develop innovative language applications and transfer them into concrete application scenarios in their respective domains. In contrast to existing cloud solutions, Gaia-X is a federated system that allows different service providers and data owners to connect with each other. The data always remains with the owner and is only shared according to defined conditions.
Teuken-7B was trained using the JUWELS supercomputer at Forschungszentrum Jülich.
Use of Teuken-7B
Interested parties from science and industry can download Teuken-7B free of charge from Hugging Face and work with it in their own development environment. The model has already been optimized for the chat by 'Instruction Tuning'. Instruction tuning is used to adapt large AI language models so that the model correctly understands instructions from users, which is particularly relevant for using the models in practice, e.g. for use in a chat application. Teuken-7B is available in two versions: a version that can be used for research purposes and a version under the 'Apache 2.0' license, which companies can use for commercial purposes in addition to research and integrate into their own AI applications. The performance of both models is roughly comparable. However, some of the data sets used for instruction tuning exclude commercial use and were therefore not used in the Apache 2.0 version.
 Comparison of Teuken-7B with other open source language models
Comparison of Teuken-7B with other open source language models
Download options and model cards can be found at the following link: https://huggingface.co/openGPT-X (call: 02.12.2024).
The OpenGPT-X Discord Server is available to the specialist community for technical feedback, questions and technical discussions: https://discord.gg/RvdHpGMvB3 (accessed: 02.12.2024).
Especially for companies, there is also the opportunity to take part in free demo sessions in which Fraunhofer scientists explain which applications can be realized with Teuken-7B. Registration for demo appointments is possible via www.iais.fraunhofer.de/opengpt-x.
Technical background information and benchmarks as well as an overview of all research results of the project can be found on the project website: https://opengpt-x.de/en/models/teuken-7b (call: 02.12.2024).
The research project, which was launched at the beginning of 2022, is now nearing completion. It will run until March 31, 2025.
www.iais.fraunhofer.de, https://huggingface.co/openGPT-X, https://discord.gg/RvdHpGMvB3, https://opengpt-x.de/en/models/teuken-7b
