")
")
")
Como parte de una tesis de graduación, se desarrolló un sistema con el que se pueden entrenar redes neuronales convolucionales (CNN) para identificar con fiabilidad componentes electrónicos en imágenes de rayos X. Para entrenar las CNN se utiliza el concepto de aprendizaje por transferencia. Se diseñó e implementó un procedimiento para generar conjuntos de datos de entrenamiento adecuados. Con la ayuda de los conjuntos de datos de entrenamiento, se pudieron entrenar y evaluar diferentes arquitecturas de red para la clasificación de imágenes y la detección de objetos. Para el aprendizaje por transferencia se utilizaron modelos de libre acceso procedentes de otro dominio. Los resultados muestran que el aprendizaje por transferencia es un método adecuado para reducir el esfuerzo (tiempo, cantidad de datos) en la creación de modelos de clasificación y detección de objetos. Los modelos creados muestran un alto grado de precisión en la clasificación y la detección de objetos, incluso con datos desconocidos. Las aplicaciones relacionadas con la evaluación de imágenes radiográficas de conjuntos electrónicos pueden diseñarse con mayor eficacia gracias a los conocimientos disponibles.
En la Parte 2 de este número se explica el concepto de aprendizaje por transferencia y se presentan los resultados del estudio.(Véase la Parte 1 en el número 10/2022)
Como parte de un proyecto de fin de carrera, se desarrolló un sistema con el que se pueden entrenar redes neuronales convolucionales (CNN) para reconocer con fiabilidad componentes electrónicos en imágenes de rayos X. Para ello se utiliza el concepto de aprendizaje por transferencia. Se diseñó un procedimiento para generar conjuntos de datos de entrenamiento adecuados. Esto permitió entrenar y evaluar diversas arquitecturas de red para la clasificación de imágenes y la detección de objetos. Para el aprendizaje por transferencia se utilizaron modelos libremente disponibles de otro dominio. Los resultados muestran que el aprendizaje por transferencia es un método adecuado para reducir el esfuerzo (tiempo, volumen de datos) que supone la creación de modelos de clasificación y detección de objetos. Los modelos creados muestran una alta precisión en la clasificación y la detección de objetos, incluso con datos desconocidos. De este modo, pueden diseñarse con mayor eficacia aplicaciones relacionadas con la evaluación de imágenes radiográficas de conjuntos electrónicos.
En la primera parte del artículo (véase el número 10/2022), se presentaron los aspectos específicos del reconocimiento de objetos en imágenes radiográficas y el uso de redes neuronales para tales tareas. A continuación se aborda la cuestión de cómo pueden utilizarse los resultados existentes en el campo del reconocimiento de imágenes en imágenes óptico-lumínicas de objetos de otros ámbitos de aplicación para obtener resultados más rápidamente.
En la parte 2 de este número se explica el concepto de aprendizaje por transferencia y se presentan los resultados del estudio.(Parte 1 véase el número 10/2022)
4 Aprendizaje por transferencia
El proceso de clasificación de imágenes mediante CNN puede visualizarse de forma compacta como se muestra en la figura 4. El modelo consta de la llamada columna vertebral y la cabeza. La columna vertebral genera características a partir de los datos de entrada aplicando filtros y crea mapas de características. Estos se clasifican en la cabeza. En una red neuronal recién inicializada, los filtros son inicialmente muy inespecíficos y se refinan y optimizan durante el entrenamiento. Sin embargo, reinicializar una CNN lleva mucho tiempo y es muy intensivo desde el punto de vista computacional, además de requerir un número muy elevado de conjuntos de datos anotados, es decir, varios cientos de imágenes por clase de objeto. En este contexto, anotación significa vincular una imagen con la etiqueta de clase correspondiente.
 Fig. 4: Proceso de clasificación de imágenes
Fig. 4: Proceso de clasificación de imágenes
La creación de un conjunto de datos suele considerarse el proceso más complejo y costoso. Sin embargo, el esfuerzo puede reducirse transfiriendo el conocimiento de una red neuronal preentrenada para resolver una tarea a una nueva tarea o aplicación. El aprendizaje por transferencia es básicamente lo mismo que la clasificación, en la que un modelo ya entrenado se modifica y se sigue optimizando.
Existen diferentes escenarios de modificación para el aprendizaje por transferencia y siguen el siguiente esquema:
- Selección de una red base
- Copia de las n primeras capas (núcleo de filtrado)
- Entrenamiento de la red con el conjunto de datos objetivo
La configuración de la red de destino (selección de la red de base, número de capas transferidas o recién inicializadas) es de libre configuración y queda a criterio del usuario. Sin embargo, los parámetros mencionados dependen del tamaño del conjunto de datos, de la similitud con el dominio de origen y de la aplicación y, por lo general, deben determinarse experimentalmente. Generalmente se recomienda, especialmente para conjuntos de datos muy pequeños, sustituir sólo la última capa por un clasificador lineal [6].
 Ausgangspunkt: Vortrainiertes Netz für eine bestimmte Aufgabe") (a) Punto de partida: Red preentrenada para una tarea específica
(a) Punto de partida: Red preentrenada para una tarea específica
 Szenario 1: Die vortrainierte Netzarchitektur wird vollständig transferiert. Die einzelnen Schichten können während des Trainings optimiert werden") (b) Escenario 1: La arquitectura de red preentrenada se transfiere por completo. Las capas individuales pueden optimizarse durante el entrenamiento
(b) Escenario 1: La arquitectura de red preentrenada se transfiere por completo. Las capas individuales pueden optimizarse durante el entrenamiento
 Szenario 2: Es werden die ersten n Schichten transferiert und die letzten zwei mit zufälligen Werten initialisiert. Die transferierten Schichten können, die neu initialisierten müssen trainiert werden") (c) Escenario 2: Se transfieren las primeras n capas y las dos últimas se inicializan con valores aleatorios. Las capas transferidas se pueden entrenar, las recién inicializadas deben entrenarse.
(c) Escenario 2: Se transfieren las primeras n capas y las dos últimas se inicializan con valores aleatorios. Las capas transferidas se pueden entrenar, las recién inicializadas deben entrenarse.
![(d) Szenario 3: Das Netzwerk wird transferiert, nach der dritten Schicht abgeschnitten und zwei neue Schichten angehängt, nach [6]](/images/stories/Abo-2022-10/plus-2022-10-1016.jpg "(d) Szenario 3: Das Netzwerk wird transferiert, nach der dritten Schicht abgeschnitten und zwei neue Schichten angehängt, nach [6]") (d) Escenario 3: La red se transfiere, se corta después de la tercera capa y se añaden dos capas nuevas, según [6].
(d) Escenario 3: La red se transfiere, se corta después de la tercera capa y se añaden dos capas nuevas, según [6].
4.1 Conjunto de datos
Los requisitos de un conjunto de datos vienen determinados en gran medida por la finalidad de la aplicación. En este estudio, se han considerado dos aplicaciones en el campo de la visión artificial. La primera es la clasificación de imágenes y la segunda es la detección de objetos.
Para la clasificación, basta con proporcionar una etiqueta por imagen. Ésta puede adoptar la forma de una estructura de carpetas en el sistema de archivos o de un archivo en el que los nombres de archivo se asignan a las clases de objetos. Para la detección de objetos, también deben proporcionarse las coordenadas del rectángulo que representa los límites del objeto.
La cantidad de datos de entrenamiento necesarios para la clasificación depende de la complejidad de la tarea y de la complejidad del modelo. En general, puede suponerse una relación lineal entre el número de parámetros optimizables y las muestras necesarias. En el caso de la detección de objetos, los requisitos son diferentes, ya que durante el entrenamiento, además de la clasificación de los objetos, también hay que aprender a diferenciarlos del fondo. Por lo tanto, la calidad de los datos desempeña un papel muy importante, además de la cantidad. Sin embargo, no se trata de la calidad de la imagen en el sentido convencional, sino de la diversidad de las imágenes. En el mejor de los casos, un conjunto de datos de alta calidad representa todas las condiciones y situaciones de disparo posibles. Para los objetos cotidianos, esto significa: iluminación, hora del día y estación del año, condiciones meteorológicas y diferentes contextos.
Para el reconocimiento de componentes electrónicos, esto significa que en la creación del conjunto de datos se incluyan tantos conjuntos y tipos y tamaños de envases como sea posible. El aumento de datos puede utilizarse para ampliar artificialmente el conjunto de datos. Esto implica transformaciones de la imagen, como reflejos, distorsiones y adición de ruido de imagen.
Los conjuntos de datos que se generaron para el entrenamiento y las pruebas se basan en datos de imágenes proporcionados por dos conjuntos diferentes de un socio industrial (véase la Tabla 2) y en imágenes tomadas en conjuntos de prueba. Para acelerar el proceso, las imágenes de rayos X de los conjuntos se anotaron automáticamente con los datos de diseño correspondientes. Para ello se estructuraron códigos 2D en la capa de cobre de la placa de circuito impreso, que son visibles en la imagen de rayos X y permiten así una asignación clara entre la sección de imagen y los datos de diseño. Al crear el conjunto de datos se tuvo en cuenta una distribución equilibrada de las clases y un alto grado de diversidad en las imágenes. De este modo, se generaron diferentes conjuntos de datos para el entrenamiento de clasificadores de imágenes y detectores de objetos.
| Conjunto de datos | Conjunto 1 | Conjunto 2 |
| Conjunto Capas Tecnologías Componentes Componentes más comunes Características especiales |  una cara una carauna capa SMT, THT 1492 objetos 9 tipos de componentes diferentes 77 variantes de encapsulado / huella Resistencia - 37 Capacitancia - 22 Diodo - 17 Producto del cliente (montaje de prueba) |  doble cara doble caramulticapa SMT, THT 783 objetos 11 tipos de componentes 57 variantes de encapsulado / huella Resistencia - 56 Capacitancia - 24 Diodo - 8,3% Producto del cliente, imagen con mayor tiempo de exposición, lo que da como resultado un bajo ruido de imagen |
Para la placa de pruebas interna se utilizaron seis tipos diferentes de componentes y encapsulados SMD. En este caso concreto, se trata de
- Resistencia de chip de tamaño 0603
- Condensador de chip de tamaño 0603
- Inductor de chip de tamaño 0402
- Diodo TVS - bidireccional, paquete: SOD-882
- Transistor, encapsulado: HUSON3 (QFN / SON)
- Diodo Schottky, paquete: SOT-143R
Para evitar una distribución desequilibrada de las clases, se colocan 50 de cada uno de los tipos de componentes anteriores en la placa de pruebas (300 componentes en total). Para conseguir la mayor variación posible en las grabaciones, los componentes no se colocan regularmente en la placa, sino de forma aleatoria. En este caso concreto, la placa tiene unas dimensiones de 80 mm x 100 mm. La disposición aleatoria de los componentes se puede ver en la Figura 6 utilizando el archivo de la placa del sistema de diseño.
 Fig. 6: Posiciones de colocación de la placa de prueba
Fig. 6: Posiciones de colocación de la placa de prueba
") Fig. 7:Marcadores Arucoestructurados en cobre, placa de prueba para analizar diferentes tamaños de estructura (por píxel: 0,25 mm, 0,5 mm, 0,75 mm, 1 mm y 2 mm)Para facilitar la posterior anotación automática de los datos de imagen, también se colocaron manualmente en la placa de circuito impreso marcadores de referencia especiales en forma de marcadores Aruco. Se trata de una estructura cuadrada con la que se codifica un número en forma de máscara de píxel. Esta estructura se estructuró posteriormente en la capa de cobre de la placa de circuito impreso junto con las almohadillas de conexión de los componentes. En la figura 7 se muestra un ejemplo de estas estructuras. Los marcadores Aruco son un sistema de marcadores de referencia que se desarrolló originalmente para y se utiliza también en el campo de la navegación robótica y las aplicaciones de realidad aumentada. Para aumentar la cantidad de datos, se toman varias imágenes por tablero, con diferentes estructuras superpuestas en el tablero de prueba.
Fig. 7:Marcadores Arucoestructurados en cobre, placa de prueba para analizar diferentes tamaños de estructura (por píxel: 0,25 mm, 0,5 mm, 0,75 mm, 1 mm y 2 mm)Para facilitar la posterior anotación automática de los datos de imagen, también se colocaron manualmente en la placa de circuito impreso marcadores de referencia especiales en forma de marcadores Aruco. Se trata de una estructura cuadrada con la que se codifica un número en forma de máscara de píxel. Esta estructura se estructuró posteriormente en la capa de cobre de la placa de circuito impreso junto con las almohadillas de conexión de los componentes. En la figura 7 se muestra un ejemplo de estas estructuras. Los marcadores Aruco son un sistema de marcadores de referencia que se desarrolló originalmente para y se utiliza también en el campo de la navegación robótica y las aplicaciones de realidad aumentada. Para aumentar la cantidad de datos, se toman varias imágenes por tablero, con diferentes estructuras superpuestas en el tablero de prueba.
Para la anotación automática de los datos de la imagen, al menos una de las marcas de referencia debe estar presente en la imagen, pero dos sería mejor. Otro requisito previo es disponer de los datos CAD asociados al tablero en forma de archivo de tablero. El uso de marcadores Aruco ofrece varias ventajas para la anotación automatizada en comparación con los marcadores de referencia habituales en forma de círculos, cuadrados o cruces. A menudo sólo se toman imágenes individuales de partes de un conjunto. Aunque en estas imágenes pueden aparecer marcas de referencia, no son únicas. Por lo tanto, puede resultar difícil asignar la región de la imagen visualizada a la posición correcta en los datos CAD. Además del número codificado, las marcas Aruco también tienen un sistema de coordenadas que se extiende a través de los bordes y también es invariable en términos de tamaño y rotación. Por tanto, las marcas Aruco pueden detectarse teóricamente con una precisión inferior al píxel.
Las marcas de referencia colocadas en la placa de circuito impreso permiten determinar el tamaño del píxel en el rango de los micrómetros. También proporcionan información sobre la posición de la sección de la imagen que se está visualizando. A partir de la posición de la marca de referencia en la imagen y del tamaño de píxel calculado, es posible asignar la posición y la sección considerada en los datos CAD. A continuación, el sistema de coordenadas de la imagen y de los datos CAD debe transformarse para que las posiciones se correspondan y pueda calcularse un desplazamiento. A continuación, es posible determinar qué componentes son visibles en la sección de la imagen. La información así obtenida sobre la imagen se guarda en una tabla. Para mejorar y ampliar el conjunto de datos se llevaron a cabo otros procesamientos, como el ya mencionado aumento de datos mediante la plataforma en línea Roboflow. La tabla 3 muestra un resumen de los conjuntos de datos creados.
Conjunto de datos | Fuente | Clases | Categorías e instancias | Total | |||
Clasificación | Interna | 6 | CC | 380 | SOD | 294 | 2226 imágenes |
CR | 361 | SOT | 417 | ||||
CL | 376 | SON | 398 | ||||
Detección 1 | Interno | 6 | CC | 398 | SOD | 391 | 144 imágenes 2459 anotaciones Ø 17 etiqueta / imagen |
CR | 388 | SOT | 470 | ||||
CL | 390 | SON | 422 | ||||
Detección 2 | Interna, externa | 1 | Componente | 3170 | 175 Imágenes 3164 Anotaciones Ø 18 etiqueta / imagen | ||
Detección 3 | Interno, externo | 7 | CC | 575 | SOD | 402 | 175 imágenes 3164 Anotaciones Ø 18 etiqueta / imagen |
CR | 775 | SOT | 579 | ||||
CL | 393 | SON | 429 | ||||
otros | 11 | ||||||
4.2 Selección de modelos
La premisa del aprendizaje por transferencia restringe la selección a modelos preentrenados de libre acceso. En principio, debe seleccionarse un modelo que sea temáticamente lo más parecido posible al dominio de destino. Sin embargo, por regla general, todos los modelos han sido preentrenados con el conjunto de datos ImageNet y están disponibles para su uso directo dentro de los marcos de aprendizaje profundo en los denominados zoos de modelos. Dado que todos estos modelos se encuentran ahora en el ámbito del reconocimiento de objetos cotidianos, no cabe esperar que el rendimiento notificado pueda transferirse al dominio de destino. La hipótesis aquí es que las arquitecturas de red planas ofrecen una ventaja, ya que tienden a extraer características inespecíficas [6, 7]. Esto puede comprobarse utilizando diferentes modelos.
El uso de imágenes de rayos X frente a imágenes de luz conlleva algunas diferencias. La diferencia más obvia es el uso de diferentes espacios de color. Otra diferencia es el comportamiento de las oclusiones. En las imágenes luminosas, también se produce una oclusión en la imagen debido a la reflexión. En cambio, en las imágenes de rayos X, la imagen se crea por transmisión y absorción de la radiación. Como resultado, una oclusión provoca una superposición en la imagen.
Aunque los tipos de imagen son tan diferentes, el ser humano las percibe de la misma manera. Por esta razón, y porque este tipo de red se utiliza con éxito en muchos otros estudios para analizar imágenes de rayos X, estos modelos también deberían ser adecuados para el propósito de este trabajo.
4.3 Entrenamiento
Para entrenar el modelo en el sentido del aprendizaje por transferencia, es necesario configurar la red objetivo. Para conjuntos de datos más pequeños, en particular, tiene sentido utilizar primero la red como un extractor de características fijas y utilizar las características extraídas como entrada para un clasificador lineal (SVM, Support Vector Machine). Esta es la configuración que se muestra en el "Escenario de transferencia 1" - Figura 5 (b). Se copia el modelo completo, se "congelan" todos los pesos y se sustituye la capa de clasificación. La capa de clasificación suele ser la última capa de la red. También se denomina "cabeza" de la red (término más utilizado).
 Fig. 8: Ilustración muy simplificada del proceso de entrenamiento de una CNN
Fig. 8: Ilustración muy simplificada del proceso de entrenamiento de una CNN
A continuación se procede al entrenamiento de una red neuronal según el esquema que se muestra en la figura 8. Este proceso se repite hasta que se alcanza un criterio de parada. Éste puede ser, por ejemplo, una precisión, una duración o un número de iteraciones a alcanzar.
Para llevar a cabo y evaluar un programa de formación, es necesario elaborar un calendario que defina las etapas necesarias. Éste suele incluir
- Cargador de datos: rutina de preparación de los datos para introducirlos en la red.
- Ajuste de hiperparámetros: definición de los distintos hiperparámetros (véase más adelante).
- Inicialización del modelo - definición de las capas adaptables / capas que se van a optimizar
- Etapa de entrenamiento
- Evaluación
El cargador de datos se encarga de transformar los datos de entrada en un formato que pueda ser utilizado por la red. Esto suele implicar el redimensionamiento, la normalización y la normalización de los valores de los píxeles. Cuando se cargan los datos de entrenamiento, también pueden modificarse para ampliar artificialmente el conjunto de datos (aumento de datos).
Los hiperparámetros se determinan experimentalmente a partir de valores estándar. Son especialmente importantes en el contexto del aprendizaje por transferencia:
- Tasa de aprendizaje: determina cuánto se modifican los parámetros en el paso de optimización. Cuanto mayor sea, más rápido olvidará el modelo la información antigua. Suele oscilar entre 10-5. . 10-3.
- Función de pérdida: mide lo bien o mal que la red predice los datos de entrada.
- Optimizador - Algoritmo que determina los nuevos pesos
- Tamaño del lote - Número de muestras por paso de entrenamiento. El número está limitado por la memoria gráfica, ya que ésta debe almacenar todos los resultados intermedios.
Una vez configurado el modelo con los hiperparámetros y la arquitectura deseada, puede llevarse a cabo el entrenamiento. En una etapa de entrenamiento, la optimización consiste en minimizar una función de coste o de pérdida. Esta función se selecciona en función del tipo de clasificador y del número de clases. Durante y después del entrenamiento, la calidad del modelo puede determinarse utilizando el conjunto de datos de prueba. Una evaluación intermedia periódica puede revelar un exceso de ajuste de la red.
4.4 Evaluación
Existen diferentes métricas y herramientas para la evaluación de redes neuronales, dependiendo de la aplicación. Para la comparación de clasificadores binarios (k = 2 clases), la precisión se especifica como Accuracy. Para los clasificadores multiclase (k > 2), se suele especificar la precisión media de todas las clases, también denominada Precisión (media). Se calcula según la ecuación <1>. Una predicción o clasificación suele considerarse correcta (verdadero positivo) si la clase predicha coincide con la clase real.
 Fig. 9: Ejemplo de cálculo de intersección sobre unión
Fig. 9: Ejemplo de cálculo de intersección sobre unión
Para evaluar el rendimiento (en términos de precisión) de los detectores de objetos se suelen utilizar las métricas de Evaluación de Detección COCO [8]. El valor comparativo más común es la precisión media (AP). Se trata de un valor medio a partir de valores medios. Para calcular el valor, se determina la precisión(Ec. <2>) para cada clase en diferentes umbrales de intersección sobre unión (IoU para abreviar, Fig. 9). Este valor también puede entenderse como precisión media (mAP). La precisión describe la relación entre los objetos reconocidos correctamente y el número de objetos reconocidos. El IoU describe el solapamiento entre el límite del objeto predicho y el límite del objeto real.
Como parte de la evaluación COCO, las métricas mencionadas también se relacionan con diferentes niveles de escala para determinar el rendimiento para objetos pequeños, medianos y grandes. Estos niveles se denominan APs, APm, APl. El área del objeto se considera en píxeles.
- pequeño 0 < área ≤ 1024
- mediano 1024 < área ≤ 9216
- grande 9216 < área
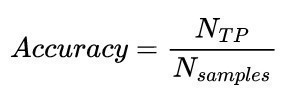 <1>
<1>
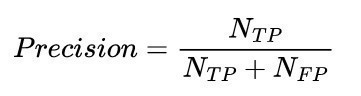
<2>
TP - Verdadero positivo, FP - Falso positivo
5 Pruebas y resultados
Para comprobar si el aprendizaje por transferencia y los modelos preentrenados pueden utilizarse en este ámbito de aplicación, se realizaron experimentos en el campo de la clasificación de imágenes y la detección de objetos. Se investigó principalmente la influencia de los hiperparámetros en el comportamiento del entrenamiento. Éstos se determinan experimentalmente a partir de valores estándar.
5.1 Clasificación de imágenes
Los modelos CNN utilizados aquí proceden de PyTorch [9]. Durante los experimentos se utilizaron las siguientes versiones de software y hardware:
- Versión de Python: 3.7.10
- Versión de PyTorch: 1.8.1
- Versión de Torchvision: 0.9.1
- Versión de W&B CLI: 0.10.32
- Tarjeta gráfica: Tesla V100-SXM2-16GB (vía Google Colab Pro)
- Versión del controlador: 460.32.03
- Versión de CUDA: 11.2
El conjunto de datos "Clasificación"(Tabla 3) se utiliza para entrenar las CNN. De cada clase, se seleccionan aleatoriamente 60 muestras para el conjunto de pruebas (N = 360); los elementos restantes se utilizan para el entrenamiento.
En la primera prueba, se entrenaron y evaluaron 30 arquitecturas de red diferentes de 10 familias con la siguiente configuración estándar.
- Tamaño del lote 256
- Optimizador SGD
- Tasa de aprendizaje 1*10-3
- Función de pérdida Entropía cruzada
En este experimento quedó claro que algunas arquitecturas de red son mejores y otras peores como extractores de características fijas. En la Figura 10 se muestra el rendimiento de algunos modelos durante el entrenamiento. Como puede verse, los modelos de la familia de VGGs y la AlexNet alcanzan una precisión superior al 95 % tras sólo 10 épocas.
 Fig. 10: Curva de precisión a lo largo del entrenamiento de distintas arquitecturas de red
Fig. 10: Curva de precisión a lo largo del entrenamiento de distintas arquitecturas de red
 Fig. 11: Influencia de diferentes tasas de aprendizaje en el entrenamiento utilizando el ejemplo de ResNet-152
Fig. 11: Influencia de diferentes tasas de aprendizaje en el entrenamiento utilizando el ejemplo de ResNet-152
 Fig. 12: Influencia de distintos tamaños de lote en el entrenamiento con el ejemplo de ResNet-152
Fig. 12: Influencia de distintos tamaños de lote en el entrenamiento con el ejemplo de ResNet-152
 Fig. 13: Influencia del tamaño del conjunto de datos
Fig. 13: Influencia del tamaño del conjunto de datos
Se realizaron pruebas prácticas con varias CNN comunes. Se comprobó específicamente su idoneidad como extractores de características fijas, ya que esto requiere especialmente pocos datos de entrenamiento. Se comprobó que la mayoría de los modelos probados ofrecen resultados entre buenos y muy buenos en este caso, mientras que otros no son adecuados. Los modelos de las familias VGG y DenseNet, así como AlexNet, mostraron los mejores resultados en esta configuración. Resultó que el parámetro Tasa de aprendizaje tiene una gran influencia en la calidad del entrenamiento(Fig. 11). Por el contrario, los modelos fueron bastante insensibles a los cambios en el tamaño del lote(Fig. 12). La investigación de la influencia de los datos necesarios para el entrenamiento reveló que el valor estimado de 100 muestras por clase era más que suficiente. Ya después de 50 muestras no se reconocieron mejoras significativas del modelo(Fig. 13).
Modelo | Tamaño del lote | AP | APs | APm | APl |
RetinaNet | 4 (valor inicial) | 58,90 | 47,07 | 58,94 | 62,47 |
2 | 60,25 | 50,54 | 60,72 | 62,14 | |
8 | 58,96 | 42,42 | 59,06 | 64,42 |
Modelo | Capa congelada | AP | APs | APm | APl |
RetinaNet (ResNet-101-FPN-3x) | 2 | 60,25 | 50,54 | 60,72 | 62,14 |
3 | 58,86 | 41,57 | 59,64 | 60,75 | |
4 | 54,18 | 50,08 | 54,54 | 55,46 | |
6 | 47,03 | 23,03 | 50,33 | 39,18 | |
10 | 44,13 | 21,91 | 47,71 | 36,18 |
5.2 Detección de objetos
En la sección anterior se demostró que las CNN son muy adecuadas para clasificar componentes electrónicos en imágenes radiográficas. Dado que las redes allí analizadas se utilizan a menudo como columna vertebral en detectores de objetos, es razonable suponer que también pueden obtenerse buenos resultados para esta aplicación. Además de Detectron2, también se utilizó la implementación YOLOv5 PyTorch [10] para entrenar el detector de objetos. Aquí se utilizaron las arquitecturas Faster R-CNN (de dos etapas) y RetinaNet (de una etapa) del Detectron Model Zoo [11]. Se analizó de nuevo la influencia del tamaño del lote en el proceso de entrenamiento y en los resultados. Se comprobó que reducir el tamaño del lote a 2 (0,5 veces el valor inicial) o aumentarlo a 8 (2 veces el valor inicial) sólo tiene un efecto menor en el entrenamiento. La Tabla 4 es un ejemplo para el modelo RetinaNet.
Modelo | Fuente de datos | Clases | APs |
YOLOv5l | interno | 1 | 65,31 |
6 | 62,11 | ||
interno + externo | 1 | 66,61 | |
7 | 68,01 | ||
 |  | ||
Detección del conjunto de datos 1 / número de clases = 1 | Detección del conjunto de datos 2 / número de clases = 1 | ||
Los objetos reconocidos como componentes se resaltan con un marco rojo | |||
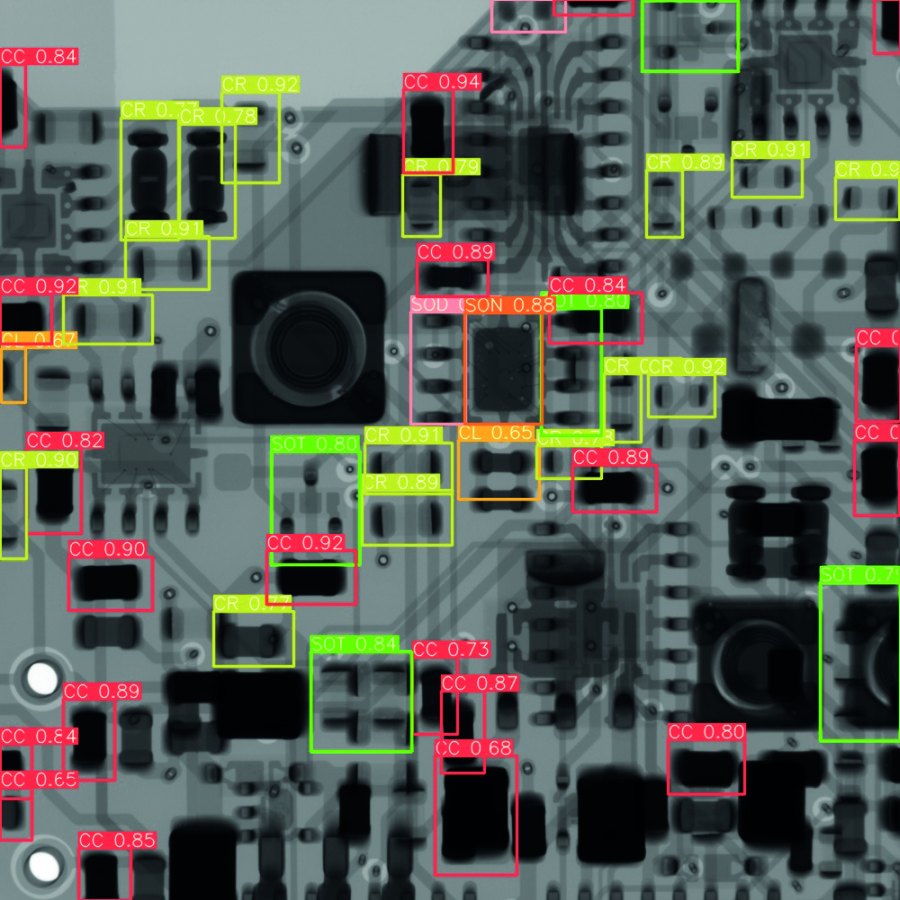 |  | ||
Detección del conjunto de datos 1 / número de clases = 6 | Detección del conjunto de datos 3 / número de clases = 7 | ||
Los componentes reconocidos que pueden asignarse a una clase con una probabilidad definida (P ≥ 50%) reciben un marco claro (CC = rojo, CL = amarillo oscuro; CR =P amarillo; SOT = verde, SOD = rosa; SON = naranja). | |||
En otro experimento, se investigó la influencia de las capas congeladas. Esto se refiere al número de capas que no se optimizan durante el proceso de entrenamiento. El ajuste por defecto es "congelar" las dos primeras capas. En los experimentos se "congelaron" 3, 4, 6 y 10 capas. Esto tuvo una gran influencia en la precisión, especialmente al reconocer objetos pequeños y grandes (Tabla 5).
Las investigaciones sobre la influencia de la tasa de aprendizaje mostraron que, en general, el aumento de la tasa de aprendizaje aumenta la precisión del modelo.
Por último, había que evaluar la influencia de la "calidad" de los conjuntos de datos de entrenamiento proporcionados sobre el resultado del reconocimiento de objetos en un objeto de prueba desconocido. Se utilizaron los siguientes conjuntos de datos y se entrenaron con el modelo YOLOv5l:
- Conjunto de datos "Detección 1" (interno), con 1 clase (detección binaria)
- Conjunto de datos "Detección 1" (interno) con 6 clases (detección multiclase)
- Conjunto de datos "Detección 2" (interna + externa) con 1 clase
- Conjunto de datos "Detección 3" (interna + externa), con 7 clases
Se ha demostrado que la calidad de la detección de objetos puede mejorarse con una mayor variedad y tamaño del conjunto de datos. La tabla 6 muestra los resultados de detección de objetos de las cuatro variantes para la misma imagen de entrada. Se trata de una sección de una imagen de rayos X de un módulo real (ordenador monoplaca Arduino), que no se incluyó previamente en ninguno de los conjuntos de datos. La fiabilidad y la cantidad de detecciones aumentan en ambos casos tras el entrenamiento con un conjunto de datos combinado.
6 Resumen
Se ha demostrado que el aprendizaje por transferencia es un método adecuado tanto para la clasificación como para el reconocimiento de objetos de componentes electrónicos en imágenes radiográficas. Por regla general, las redes neuronales requieren una base de datos muy grande para poder reconocer los patrones y estructuras subyacentes. El enfoque elegido aquí permite transferir el conocimiento de una red neuronal de un dominio de origen a un dominio de destino. Se ha demostrado que esto puede reducir significativamente los datos requeridos y el tiempo necesario para el entrenamiento. Los conjuntos de datos de entrenamiento adecuados pueden generarse con un esfuerzo manejable, pero cada vez estarán más disponibles. También existe un gran número de plataformas de software adecuadas y modelos ya preparados que pueden adaptarse a requisitos específicos sin necesidad de conocimientos profundos de programación. Se puede encontrar una descripción detallada de todo el trabajo y los resultados obtenidos en [12].
Bibliografía
[6] J. Yosinski; J. Clune; Y. Bengio; H. Lipson: How transferable are features in deep neural networks?, Adv. Neural Inf. Process. Syst., vol. 4, n.º enero, 2014, 3320-3328.
[7] D. Soekhoe; P. van der Putten; A. Plaat: On the impact of data set size in transfer learning using deep neural networks, 2016, 50-60.
[8] Consorcio COCO, Evaluación de la detección COCO, Objetos comunes en contexto COCO, 2022. https://cocodataset.org/#detection-eval
[9] Modelos y pesos preentrenados, https://pytorch.org/vision/stable/models.html
[10] ultralytics/yolov5: YOLOv5 en PyTorch, https://github.com/ultralytics/yolov5
[11] facebookresearch/detectron2: Detectron2 es la plataforma de nueva generación de FAIR para la detección de objetos, la segmentación y otras tareas de reconocimiento visual, https://github.com/facebookresearch/detectron2
[12] J. Schmitz-Salue: System design for transfer learning of neural networks for object recognition of electronic component types in radiographic images, tesis de diplomatura, TU Dresden 2021
