Das große KI-Sprachmodell des Forschungsprojekts OpenGPT-X steht ab sofort auf Hugging Face zum Download bereit: Das Modell mit dem Namen ‚Teuken-7B' wurde mit allen 24 Amtssprachen der EU trainiert. Akteure aus Forschung und Unternehmen können das kommerziell einsetzbare Open-Source-Modell für ihre eigenen Anwendungen der künstlichen Intelligenz (KI) nutzen.
The large AI language model of the OpenGPT-X research project is now available for download on Hugging Face: The model, called 'Teuken-7B’, has been trained with all 24 official languages of the EU. Researchers and companies can use the commercially usable open source model for their own artificial intelligence (AI) applications.
Das geförderte Konsortialprojekt unter der Leitung der Fraunhofer-Institute für Intelligente Analyse- und Informationssysteme IAIS und für Integrierte Schaltungen IIS hat ein großes KI-Sprachmodell als frei verwendbares Open-Source-Modell mit europäischer Perspektive auf den Weg gebracht. Im Projekt OpenGPT-X haben die Partner aus Wissenschaft und Wirtschaft in den vergangenen zwei Jahren die grundlegende Technologie für große KI-Fundamentalmodelle erforscht und entsprechende Modelle trainiert. Das daraus entstandene Modell ‚Teuken-7B' steht nun weltweit frei zur Verfügung und damit eine aus der öffentlichen Forschung stammende Alternative für Wissenschaft und Unternehmen.
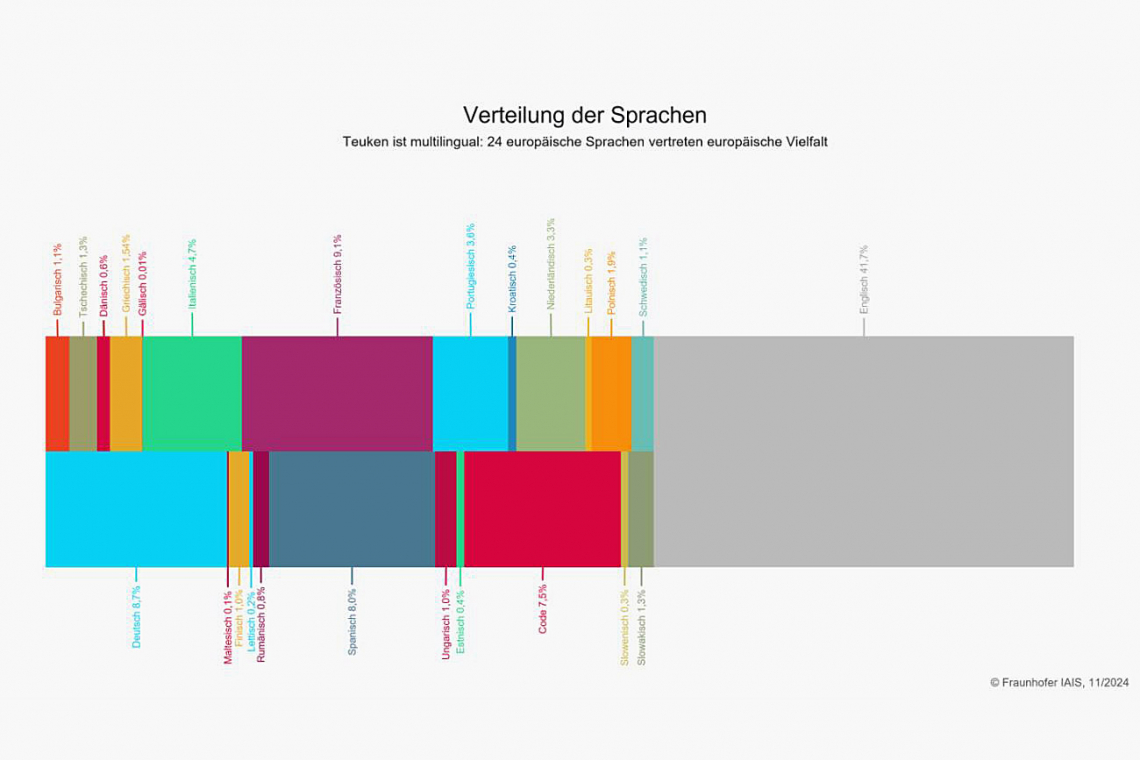
Teuken-7B ist aktuell eines der wenigen KI-Sprachmodelle, die von Grund auf multilingual entwickelt wurden. Es enthält ca. 50 % nicht-englische Pretraining-Daten und wurde in allen 24 europäischen Amtssprachen trainiert. Es erweist sich über mehrere Sprachen hinweg in seiner Leistung als stabil und zuverlässig. Dies ist insbesondere für internationale Unternehmen, die in vielen Sprachen kommunizieren, ein entscheidender Vorteil. Die Bereitstellung als Open-Source-Modell erlaubt es, eigene angepasste Modelle in realen Anwendungen zu betreiben. Sensible Daten können im Unternehmen verbleiben.
Das Projektteam widmete sich auch der Frage, wie multilinguale KI-Sprachmodelle energie- und kosteneffizienter trainiert und betrieben werden können. Dazu wurde im Projekt ein multilingualer ‚Tokenizer' entwickelt. Die Aufgabe eines Tokenizers ist es, Wörter in einzelne Wortbestandteile zu zerlegen – je weniger Token, desto (energie-)effizienter und schneller generiert ein Sprachmodell die Antwort. Der entwickelte Tokenizer führte zu einer Reduzierung der Trainingskosten im Vergleich zu anderen multilingualen Tokenizern, wie etwa Llama3 oder Mistral. Dies kommt insbesondere bei europäischen Sprachen mit langen Wörtern wie Deutsch, Finnisch oder Ungarisch zum Tragen. Auch im Betrieb von mehrsprachigen KI-Anwendungen können damit Effizienzsteigerungen erreicht werden.
Teuken-7B ist auch über die Gaia-X Infrastruktur zugänglich. Akteure im Gaia-X-Ökosystem können so innovative Sprachanwendungen entwickeln und in konkrete Anwendungsszenarien in ihren jeweiligen Domänen überführen. Im Gegensatz zu bestehenden Cloud-Lösungen handelt es sich bei Gaia-X um ein föderiertes System, über das sich unterschiedliche Dienstanbieter und Dateneigentümer miteinander verbinden können. Die Daten verbleiben stets beim Eigentümer und werden ausschließlich nach festgelegten Bedingungen geteilt.
Trainiert wurde Teuken-7B mithilfe des Supercomputers JUWELS am Forschungszentrum Jülich.
Nutzung von Teuken-7B
Interessierte aus Wissenschaft und Wirtschaft können Teuken-7B bei Hugging Face kostenfrei herunterladen und damit in der eigenen Entwicklungsumgebung arbeiten. Das Modell wurde durch ein ‚Instruction Tuning' bereits für den Chat optimiert. Mit Instruction Tuning werden große KI-Sprachmodelle dahingehend angepasst, dass das Modell Anweisungen von Nutzern richtig versteht, was vor allem für die Anwendung der Modelle in der Praxis relevant ist, z. B. für den Einsatz in einer Chatanwendung. Teuken-7B steht in zwei Varianten zur Verfügung: einer Version, die für Forschungszwecke genutzt werden kann, und einer Version unter der Lizenz ‚Apache 2.0', die Unternehmen neben der Forschung auch für kommerzielle Zwecke nutzen und in eigene KI-Anwendungen integrieren können. Die Leistungsfähigkeit beider Modelle ist in etwa vergleichbar. Einige der für das Instruction Tuning verwendeten Datensätze schließen jedoch eine kommerzielle Nutzung aus und wurden aus diesem Grund in der Apache 2.0-Version nicht verwendet.
 Vergleich von Teuken-7B mit anderen Open-Source-Sprachmodellen
Vergleich von Teuken-7B mit anderen Open-Source-Sprachmodellen
Download-Möglichkeit und Model Cardsfinden sich unter folgendem Link: https://huggingface.co/openGPT-X (Aufruf: 02.12.2024).
Fürtechnisches Feedback, Fragen und Fachdiskussionensteht der Fachcommunity der OpenGPT-X Discord Server zur Verfügung: https://discord.gg/RvdHpGMvB3 (Aufruf: 02.12.2024).
Speziell für Unternehmen besteht zudem die Möglichkeit, ankostenfreien Demoterminenteilzunehmen, in denen Fraunhofer-Wissenschaftlerinnen und Wissenschaftler erläutern, welche Anwendungen mit Teuken-7B realisiert werden können. Die Anmeldung zu Demoterminen ist über www.iais.fraunhofer.de/opengpt-x möglich.
Technische Hintergrundinformationen und Benchmarkssowie eine Übersicht aller Forschungsergebnisse des Projekts finden sich auf der Projektwebseite: https://opengpt-x.de/en/models/teuken-7b (Aufruf: 02.12.2024).
Das Anfang 2022 gestartete Forschungsprojekt steht nun kurz vor dem Abschluss. Es läuft noch bis zum 31. März 2025.
www.iais.fraunhofer.de, https://huggingface.co/openGPT-X, https://discord.gg/RvdHpGMvB3, https://opengpt-x.de/en/models/teuken-7b
